
분명 모델을 저장하는 과정에서는 문제가 없었는데, 모델을 불러오면 문제가 생겼다. strict옵션을 넣고 강제로 모델을 load할 수 있긴 하지만, 시드값을 맞추어도 실험의 재현이 되지 않았다.
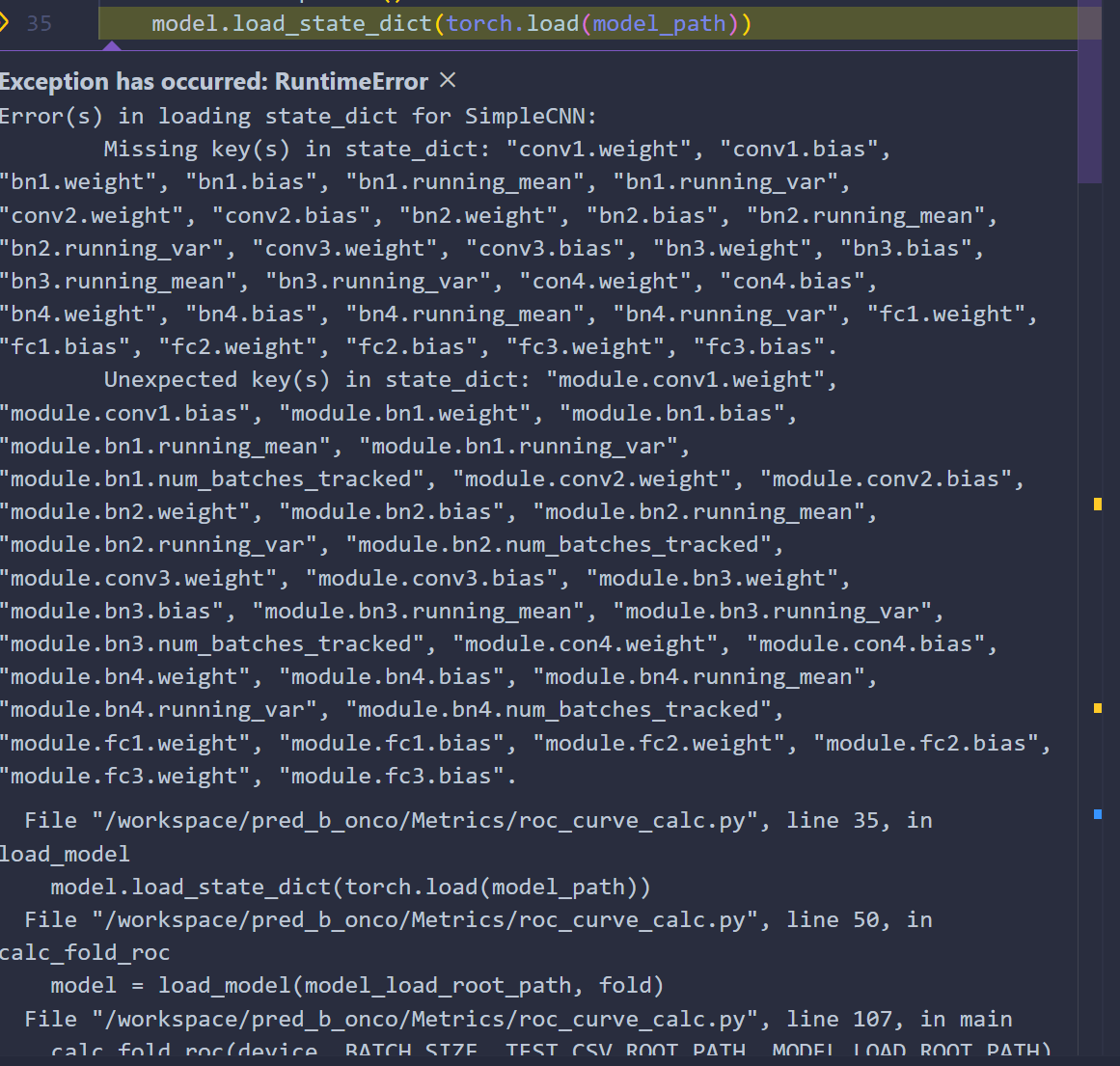
해당 사진을 보면 저장한 모델의 값을 불러올 때 Missing key에러가 발생하는데 Unexpected key가 발생한 내역을 살펴보면 모든 key앞에 module가 붙어있다.
다음과 같이 모델의 state_dict()를 저장할 때, module.state_dict()를 저장하면 됐다.
def save_model(net, save_path):
# torch.save(net.state_dict(), save_path)
torch.save(net.module.state_dict(), save_path)
print('Training process has finished. Saving trained model.')
모델 저장 관련 유의점
load_state_dict()함수는 저장된 객체의 경로가 아니라 딕셔너리 객체를 받는다. 즉, load_state_dict() 함수에 전달하기 전에 저장된 state_dict를 deserialize 해야한다.
model.load_sate_dict(PATH) # 에러 발생
model.load_state_dict(torch.load(model_path)) # 정상 사용
가장 성능이 좋은 모델만 유지하려는 경우 다음과 같은 코드는 copy가 아닌 refrence를 반환한다는 것을 유의해야 한다.
best_model_state = model.state_dict()
best_model_state를 serialize하거나, deepcopy를 사용하지 않으면 후속 training iteration에서 best_model_state는 model.state_dict()를 따라 계속 업데이트되므로, 최종모델 상태는 overfitted model 상태가 된다.
best_model_state = deepcopy(model.state_dict())
Inference를 하기 전에 model.eval()을 호출하여 dropout 및 batch normalization layer를 inference 모드로 설정해야 한다. 이렇게 하지 않으면 일관성 없는 추론 결과를 얻게 된다.
Save/Load Entire Model
Save:
torch.save(model, PATH)
Load:
# Model class must be defined somewhere
model = torch.load(PATH)
model.eval()
Saving & Loading Model Across Devices
Save on GPU, Load on CPU
Save
torch.save(model.state_dict(), PATH)
Load
device = torch.device('cpu')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location=device))GPU로 학습된 모델을 CPU에서 로드할 때는 torch.load()함수의 map_location 인수에 torch.device('cpu")를 전달하면 된다. 이 경우 텐서의 기반이 되는 저장소는 map_location 인수를 사용하여 CPU 장치에 동적으로 리매핑된다.
Save on GPU, Load on CPU
Save
torch.save(model.state_dict(), PATH)
Load
device = torch.device("cuda")
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.to(device)
# Make sure to call input = input.to(device) on any input tensors that you feed to the model
Saving `torch.nn.DataParallel` Models
Save:
torch.save(model.module.state_dict(), PATH)
Load:
위 방식과 동일
torch.nn.DataParallel은 병렬 GPU 활용을 가능하게 하는 model wrapper이다. 일반적으로 DataParallel model을 저장하기 위해서는 model.module.state_dict()를 저장해야 한다. 이 방식은 모델을 load할 때 원하는 device에 원하는 방식으로 모델을 유연하게 load할 수 있다.
참고자료
'Python 관련 > Pytorch' 카테고리의 다른 글
| [Pytorch] torchview를 사용한 모델 plot 시각화 (ubuntu) (0) | 2024.05.29 |
|---|---|
| RuntimeError: CUDA error: device-side assert triggered (0) | 2024.04.05 |
| Albumentation Color jitter 사용 오류 (0) | 2024.04.05 |
| [Pytorch] Generator (0) | 2024.02.27 |
| [Pytorch] Randomness 제어 (0) | 2024.02.27 |